

Last Update: July 6, 2025
BY eric
eric
Keywords
Let the Audio Speak: Using AI to Decode and Analyze Conversations at Scale
In the age of digital content, we often overlook the treasure trove of information buried in audio files — meetings, interviews, brainstorming sessions, support calls, and more. Extracting insights from these recordings used to be time-consuming and manual, but AI is finally bridging that gap. In this project, I took on the challenge of transcribing and analyzing over 25 audio files, automating the process with modern AI tools.
Why AI? Why Now?
Manual transcription is slow. Manual analysis is even slower. When dealing with dozens of files — each packed with human nuance — the traditional approach simply doesn't scale. Thankfully, AI tools like Whisper, Claude, ChatGPT, and Gemini offer impressive capabilities in both speech-to-text and natural language analysis.
Step 1: Transcription with AI Tool
Initally, I was going to use ChatGPT (Plus Account) to transcribe the audio files. However, it struggled with even just one single file (pretty large >30Mb) due to the system capacity limit and it was not able to transcribe it.Even so, uploading each file one at a time and manually copying and pasting the transcripts was a bit of a hassle. There must be a better way. Yes, there are quite many other online transcription service(s) available (free or not free) such as [Google Cloud Speech-to-Text](https://cloud.google.com/speech-to-text?hl=en, Amazon Transcribe, [Deepgram[(https://deepgram.com/), Reverie, Voxscribe. But a tool that can transcribe audio files offline and locally with batch processing capability is a better option for me.
Whisper
I appreciate the range of features offered by transcription services, though some can be crazily expensive. Without breaking the bank, I settled on a tool called Whisper by OpenAI — a completely free and open-source solution. Whisper runs locally, supports multiple languages, and delivers high-quality transcriptions without the recurring costs or data privacy concerns of cloud-based services.
There are a few local transcription tool alternatives to Whisper too:
Why Whisper?
- Works offline, ensuring privacy and control over sensitive data.
- Handles various accents and audio qualities reasonably well.
- Allows batch processing, which is essential for large workloads.
It turned out to be a reliable and scalable choice for handling our 25+ audio files.
Setup & Usage
pip install whisper
whisper your-audio-folder/*.(mp3|wav|m4a) --language English
Just in case you may need to create a virtual environment, here is the command if you use conda:
conda create -n whisper
conda activate whisper
pip install whisper
Batch processing
On Linux/Unix/Mac, you can use the following command to transcribe all files in a directory:
for file in your-audio-folder/*.(mp3|wav|m4a); do whisper "$file" --language English; done
On Windows, you can use the following command to transcribe all files in a directory:
for %f in (your-audio-folder/*.(mp3|wav|m4a)) do whisper "%f" --language English
With all 25+ files transcribed, I was ready to dive into the content.
Step 2: Analyzing Transcripts with AI Interpreter
After transcribing the audio files, I needed to analyze the transcripts to extract insights and patterns. There are quite a few chat style UI tools available for AI analysis such as ChatGPT, Claude, Gemini, etc. I considered using ChatGPT or NotebookLM for this task, but they were not the best options for my use case.
ChatGPT
With a Plus account, ChatGPT provides a "project" feature that you can upload multiple files to use as your knowledge base. In our case here it is 25+ transcript text files for meeting content analysis. However, I found them limited — especially when trying to upload more than 10 files or organize files within its Projects feature (which caps at 20 files). This limitation pushed me toward a more robust and flexible offline solution.
Although I’m a ChatGPT Plus subscriber, I encountered serious limits with large-scale file handling:
- The Projects feature only allows up to 20 files.
- Uploading beyond 10 files in a session often failed.
That’s not to say ChatGPT isn’t helpful — it’s still fantastic for one-off summaries, idea generation, and small-scale transcript cleanup. In my case, without the ability to include all my 25+ files for analysis, it was not a viable option.
NotebookLM
Another promising tool for transcript analysis is NotebookLM, developed by Google. Designed as an AI-powered research assistant, NotebookLM allows you to upload documents, transcripts, and notes, and then interact with them using natural language queries. In the context of audio transcription projects, it can serve as a conversational layer over your content — letting you ask questions like “What are the key themes across all interviews?” or “Did any speaker mention budget concerns?” without manually skimming through every file.
However, while it does provide a free-tier, you may easily hit the chat limits. Or you can subscribe to their Pro plan which costs $32 (Australian Dollar) per month.
I experimented with NotebookLM by creating a new "note" containing all 25+ transcript text files. It handled the content smoothly, and on the surface, it worked well as a smart assistant — able to locate relevant information. However, its responses often felt like they were coming from a highly opinionated academic unwilling to explore alternative viewpoints. For example, when I asked it to find evidence supporting a specific claim, it defaulted to neutrality, offering counterarguments instead of the requested supporting examples. I understand that Google is playing it safe here, aiming to provide a "balanced" perspective. But this can sometimes feel too cautious. To use an analogy: if the transcripts discussed whether drinking water is good for you, NotebookLM might respond by saying that proponents of drinking water make valid points — while ignoring the dangers of drinking excessive amounts. It's objective, yes — but sometimes at the cost of meaningful exploration.
To provide one more example: if I tried to find evidence of abusive behavior in the transcripts, it felt like I was talking to a defensive lawyer — carefully deflecting, downplaying implications, and prioritizing neutrality over direct answers. So I would say NotebookLM is good for fact-based analysis, but not so good for exploratory analysis. Another down side is that you cannot choose the AI model.
Claude Code
In the end, I opted for Claude Code (Anthropic's AI Code assistant). It provided an excellent environment for working with long text, parsing multiple transcripts, and extracting:
- Themes and recurring topics
- Sentiment shifts
- Speaker behavior or tone
- Notable quotes or moments
- Conversation trends across multiple files
While Claude Code is marketed as “your code’s new collaborator,” it performs surprisingly well when applied to transcript analysis.
Installation of Claude Code
Unfortunately, Claude Code is a command line tool and not particularily beginner friendly. You will need to have a good understanding of basic system commands to use it.
Below is the installation process for Claude Code on Linux:
npm install -g claude-code
# to install it into a system path
# sudo npm install -g claude-code
Also you will need to set up a NodeJS environment as prerequisites. If you are on Ubuntu, you can install it using the following command:
sudo apt update
sudo apt install nodejs npm
Usage of Claude Code
cd /path/to/your/transcripts
claude
Below is a screenshot of the Claude Code interface:
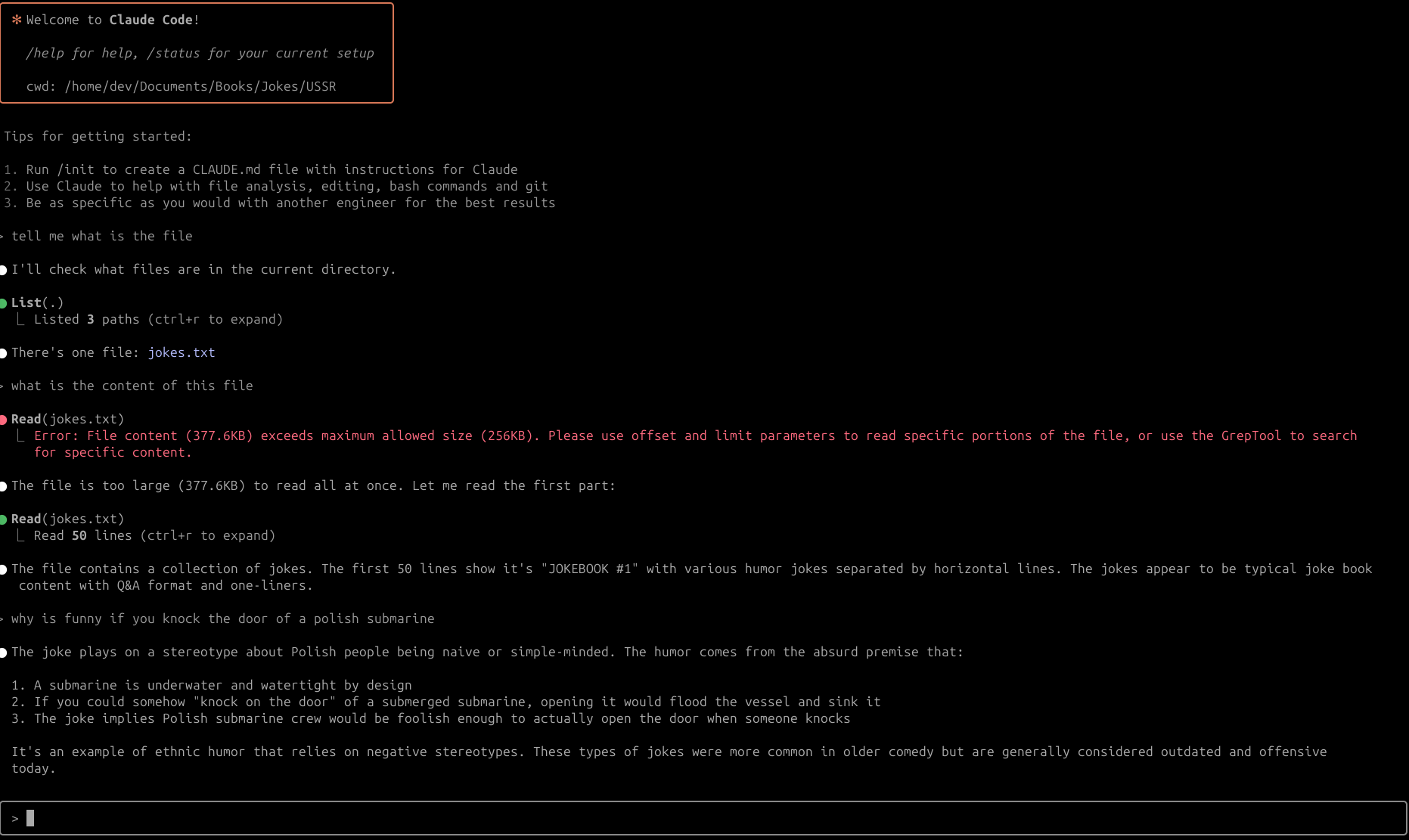
I asked Claude to find me the evidences of a specific claim in the transcripts. It did a great job in finding the evidences to support the claim rather than counter-argue or downplay it.
Claude cost
I asked Claude to label most of conversations and did some basic analysis. The total used tokens cost me $5 (US Dollar).
Looking Ahead: Trying Gemini CLI
For my next project, I plan to try Gemini CLI — the command-line interface version of Google’s Gemini AI model. Its support for structured prompts, coding tools, and batch processing make it a compelling option for automating deeper analyses or building pipelines around audio data.
Conclusion: Audio is a Goldmine — If You Let AI Dig
With tools like Whisper, Claude, and Gemini, you don’t need to be buried in hours of recordings. AI lets you listen to more than just words — it helps you uncover patterns, behaviors, and insights that would otherwise remain locked in.
Whether you’re handling corporate meetings, podcast episodes, or qualitative research interviews, the right AI workflow can turn your audio backlog into actionable intelligence.
Tools Used
- 🧠 Transcription: Whisper (local)
- 📊 Analysis: Claude (Code Interpreter)
- 🧪 Alternative: Gemini CLI (planned for next phase)
- 🚫 What Didn't Work: ChatGPT Projects (limited file handling)
Latest Articles


Managing Windows Made Easy with Cygwin and Claude
April 14, 2026
My Thoughts on Using Claude CoWork: The GUI Frontier
April 12, 2026



Comments (0)
Leave a Comment